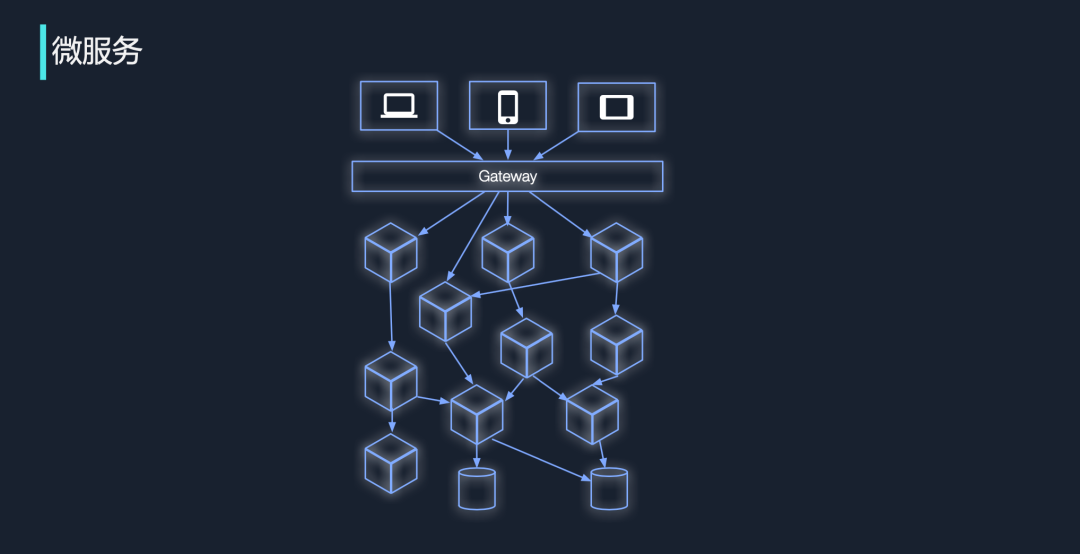
那么什么是超复杂呢?最开始的时候,很多团队可能都采用单体架构,随着业务演进、团队扩充,我们需要对服务进行逐步拆分。因此随着业务变得复杂,我们的调用链、调用网也会变得越来越复杂。当它们复杂到一定的程度时,很多难缠的问题就出现了。
当前很多团队在进行微服务化的过程中,可能暂时仅看到微服务的优势,未遇到服务管理上的问题,毕竟不是每一套系统都达到了超复杂的标准,但是提前关注这些问题并做好预案也非常重要。作为企业的软件架构师或是技术负责人,我们应当始终用发展的眼光看问题,软件行业的发展变化非常巨大,如果企业当下的架构无法适应未来一到两年的业务发展,那会对业务和技术进步形成巨大阻碍。如果架构师能吸取其他企业的教训和经验,提前布局,那么业务在扩张过程中遇到的技术问题会少很多。
01
超复杂调用网带来的难题
我个人对超复杂调用网给出一个定义:
内网非测试的微服务达 1000 个以上
至少存在一个微服务,且其实例数达到 300 个以上
对外 API 普遍涉及至少 10 个微服务
在内部技术实践中,我们发现系统达到这个量级后,超复杂调用网就会产生许多棘手的问题。
第一个要点是微服务的数量。如果一个系统内的微服务数目只有几百个,那么绘制一张囊括所有微服务的调用图是有利于管理的;但如果超过了 1000 个,再把它们塞到一张图后整张图变得不可读,它的意义就不大了。
第二点,如果一个微服务的实例数只有几十个,这时实例的管理是比较简单的,如果实例数超过 300,那么团队不可避免地会需要使用一些分片策略或是长连接策略,它们都会带来一些特殊问题。
第三点是单个 API 涉及的微服务数量。如果 API 需要普遍涉及 10 个以上的服务,这时监控会面临更大的挑战。以字节跳动的场景为例,目前字节跳动内网的在线微服务数量在万级,其中最大的微服务大约有 1-2 万个实例,而单个 API 也普遍在后端关联了几十个甚至上百个微服务。面对这样的复杂度,有三个问题最为突出:
一是难以做容量预估。微服务已经达到了一定的复杂度,它们的调用关系是非常复杂的:一个核心服务的依赖链可能就有几百个,对每个依赖方做调研或去细致地跟进每个限流策略显然非常困难。另外,不同业务会通过不同活动实现业务增长,对核心服务来说,追溯每个业务的增长也是一个非常艰巨的任务。
二是会大幅提高服务治理难度。这里的服务治理包含限流、ACL 白名单、超时配置等,因为调用关系变得复杂,每个服务可能会调用几十个甚至上百个依赖服务,一些核心服务也会被几百个服务所依赖,这时如何梳理这些调用关系、配置多少限流、配置怎样的白名单策略,就成了团队需要深度探讨的问题。
三是容灾复杂度增大。在复杂的调用关系下,每个 API 会依赖大量的微服务,而每一个微服务都有一定概率产生故障。我们需要区分强依赖和弱依赖,并辅以特定的降级策略,才能够在不稳定的服务环境下获得尽可能稳定的对外效果。
02
业界尝试
那么对于这些复杂的治理难题,业界会有怎样的尝试呢?
第一种方式是鸵鸟心态。完全不做工作,这反而是业界最广泛的尝试。相信很多企业并不是没有受到超大规模调用网的侵扰,也不是没有对其做一些尝试,而是解决问题所产生的成本和损失实在是难以量化。
举个例子,一个核心服务有很多依赖方,其中一个依赖方的代码中存在严重的重试漏洞,瞬间产生大量重试把核心服务给压垮了,最终造成了系统级的灾难。这时我们可以去追溯问题的直接原因——代码质量问题,至于隔离没做好、超复杂调用关系没有梳理清楚等,这些会被归结为间接原因,往往可以不被追究。
第二种方式是精细化的监测与限流。业内一些开源组件在功能上确实做得比较出色。如左图是一个知名开源组件,它会对整个服务链路进行精细化监控。在这个示例里,每个三角形是一个 Gateway,中空圆形才真正的服务。它展示了从流量入口到每个微服务的整个链路,如果链路是绿色的,说明流量是健康的;链路是红色的,就说明流量存在异常。有了这样详细的拓扑图,开发者就可以看清它的依赖关系。
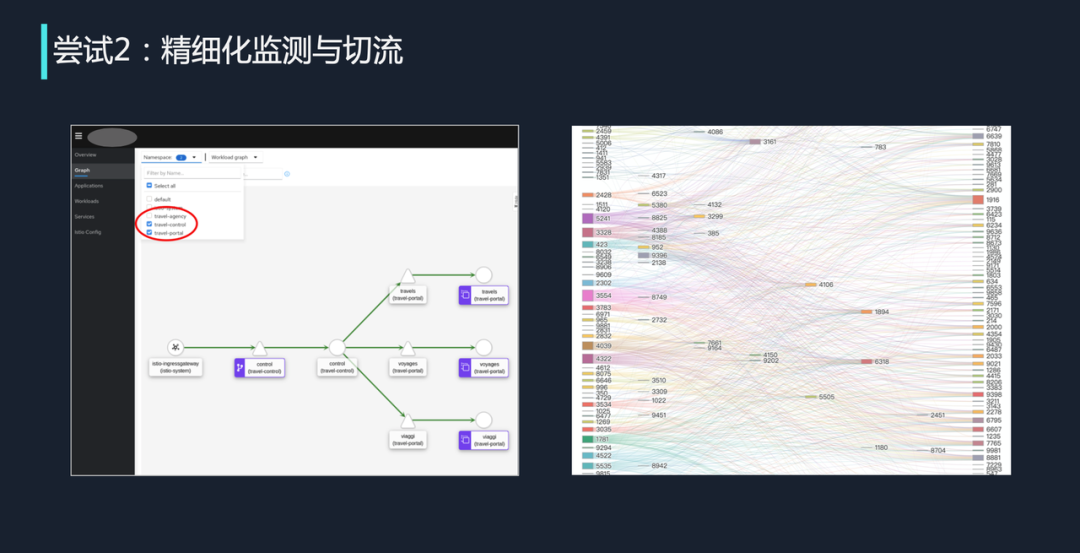
这看起来很美好,所以大概在两年前,我选取了一个中等规模的业务线,把所有依赖关系梳理出来,得到了上图中右侧这张图。里面每一个代号都是一个服务,每一条线都是这个服务的依赖关系——这实在是太复杂了。左图由于只有 4 个服务,整体比较清晰,但如果是几百个服务相互交织、相互依赖,用这种图来进行测算无疑是不可行的。
第三种方式是单元化,或称 SET 化,比较有代表性的是蚂蚁和美团。他们采用的主要方式是把每一个服务部署多份:set 1、set 2、set 3,流量通过单一的 shard key 进行 set 的选择。这样,set 之间就可以进行有效的资源隔离,在单个 set 产生问题时可以通过切流的方式容灾。
但它也有三方面的局限性。第一方面,SET 化需要有合适的分片键,如用地域或账号去切分,这需要和业务属性有匹配,并不是所有的业务都能找到这种合适的分片键。第二方面,这种方式需要的非全局数据比较多,譬如本地生活订单,用户在北京下单酒店的数据没必要经过深圳。但在抖音、今日头条这些综合信息服务场景中,非全局数据非常少,那些看似本地的数据如用户名、用户的粉丝数、近期的点赞列表,其实也是全局数据。最后一个方面,SET 化需要冗余,需要备份成本,大体量的公司不一定能够支撑。
第四种方式是 DOMA。它的英文全称是 Domain-Oriented Microservice Architecture。2020 年,Uber 提出了这个架构。下图是一个简单示例,其中绿色是 public interface,红色的是 private interface。如果有流量想访问域内的一个微服务,它必须要经过 Gateway Service 进行转发,然后才能访问。
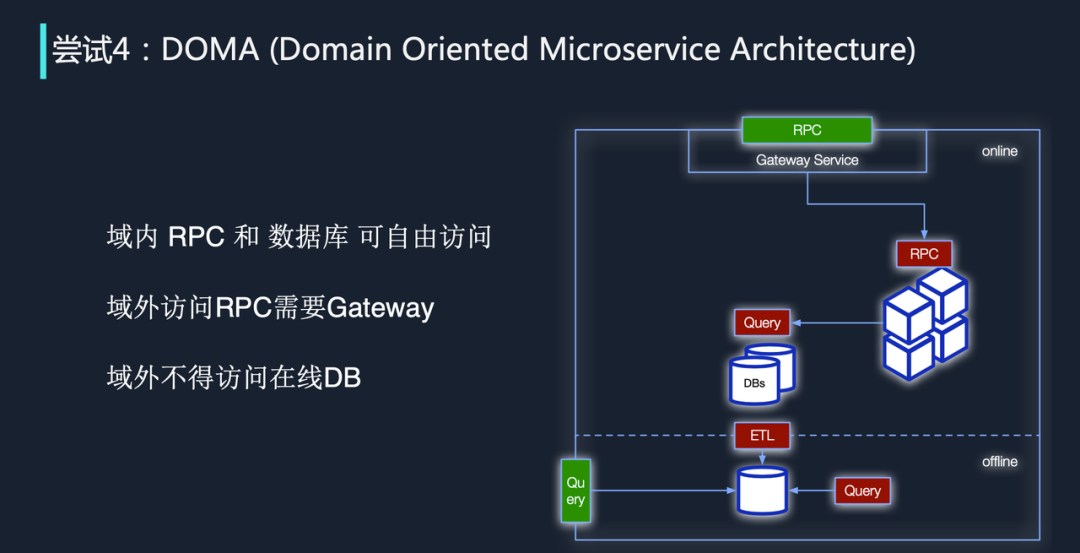
如果用户想要在域外访问这个数据库,我们需要通过左下角的 Query、ETL 把它转化成一个离线数据库。整个大框是一个 domain,它不同于 DDD 的 domain,它被称为服务域,可以理解成是一组服务的集合。字节跳动内部也参考了这种 domain 的思想,把一些服务聚合起来,产生特殊的化学反应。
但 DOMA 架构也存在一些问题,比如它过了一层 Gateway Service。我们在外层其实已经有一个从外网到内网的 Gateway,如果内网再放置过多 Gateway(尤其是中心化的),肯定会带来额外的性能消耗,并造成一定的延迟上涨,这也是字节跳动没有采取这种方式的原因。
03
字节跳动的探索和实践
对于超复杂调用网,字节跳动探索出了一些最佳实践,其中第一个核心叫做服务分层原则。
正如前文的微服务架构图所示,服务在经历从上到下的调用后出现了很复杂的调用关系,对此,我们可以依据康威定律对它做一些横向切分,对调用关系进行分层。
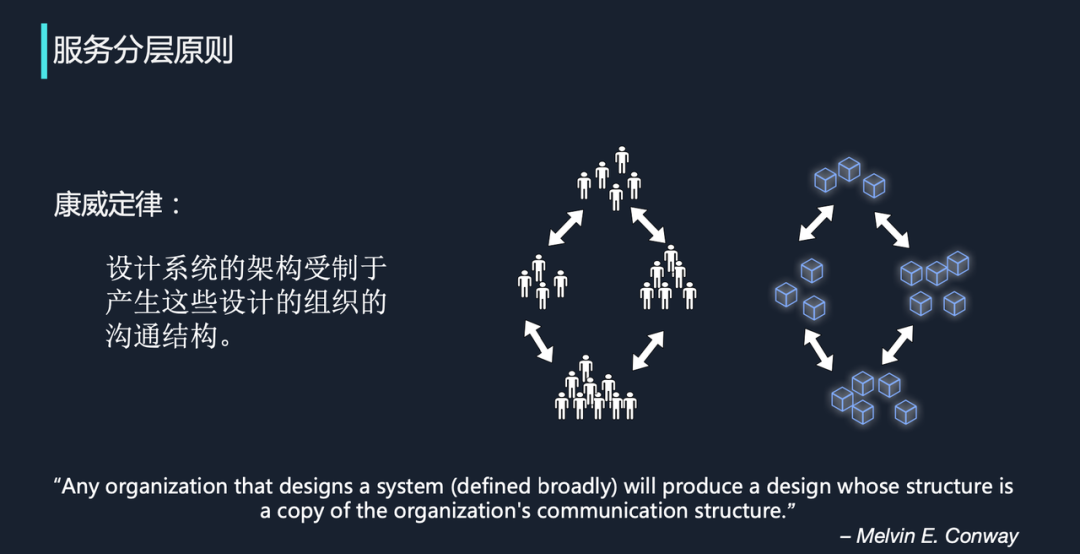
康威定律是马尔文·康威于 1967 年提出的,指的是设计系统的架构受制于产生这些设计组织的沟通结构。举个例子,假设某家公司内部有四个团队,如上图所示,左侧团队和上方团队沟通较密切,上方团队和下方团队沟通较少,把这种关系映射到微服务架构中后也是类似的,上方微服务和左侧微服务的通信耦合性会大一些,和下方微服务的联系就会弱一些。
我们之前讨论过一个悖论:为什么企业的组织架构非常清晰,但是微服务设计就非常复杂?最终得出的结论是没有做好映射。字节跳动内部有很多团队分别负责业务、中台、基础架构等技术领域,在真实的微服务架构下,我们应该把它清晰地切分成不同层次。
如下图所示,首先是网关层。外网到内网之间需要有一个 Gateway 来处理一些基本事项,如参数基础校验、session 机制、协议转换等。
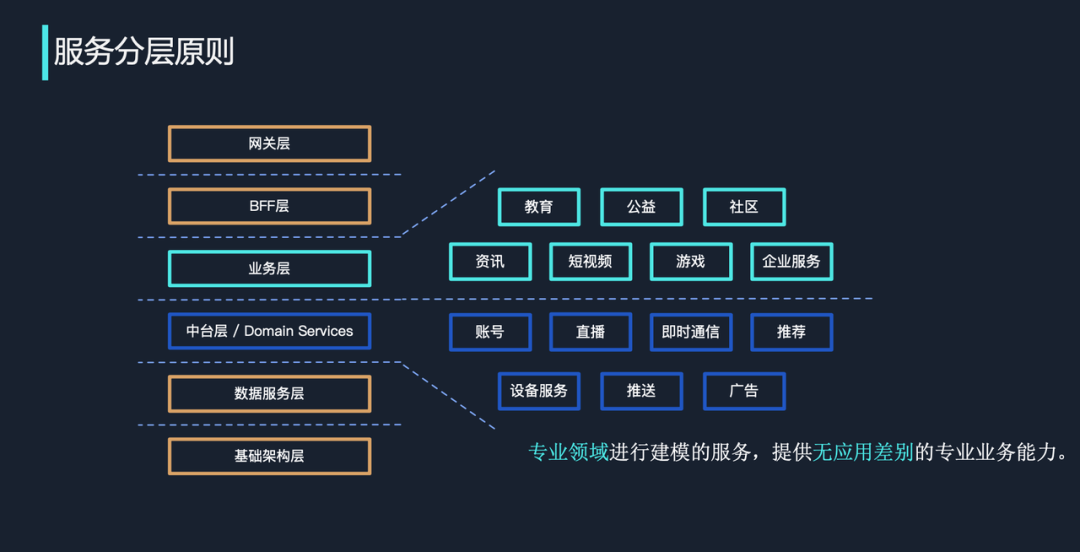
第二层是 BFF 层。BFF 是近几年日趋流行的一个概念,全称是 Backend For Frontend(服务于前端的后端)。如过一个接口的对外主体业务逻辑是一致的,但在 iOS、Android、Web 等不同客户端的可能有一些细微差别,那么这些差别可以放在 BFF 层处理。
第三层是业务层。字节跳动有很多业务,如短视频、资讯、游戏、公益等,与特异业务功能直接相关的功能应当由这一层来实现。
第四层是中台层,这一层应用了 DDD 的思想,我们抽取了一些通用的特殊能力,对它们进行专业化的建模和封装,以实现大量基础能力的复用。
第五层是数据服务层,通过合理的封装,用户无需直接访问数据库的表即可更方便、更安全地使用数据。
最后一层是基础架构层,这层主要提供基础架构领域的各种能力,比如微服务基础组件、微服务基础依赖以及数据库或是消息队列等。
字节跳动之所以可以快速孵化新产品,业务层和中台层的建设是一个重要原因。比如新做一个教育应用,我们可以直接调用成熟的账号系统、支付系统、直播模块等,也可以通过向学员推送他可能感兴趣的视频,将他们转化成付费会员。由于存在这类专业领域的建模,在对微服务进行归类处理时,分层变得尤为重要。
这里有几个指导思想供大家参考:首先是分层原则需要结合业务灵活调整,DDD 只是一种指导思想,不能按照它的每一条规范去做;其次是在分层原则中,建议从上到下去进行访问,业务层的请求可以访问数据服务层,但数据服务层的请求不能访问中台层,逆向访问可能会产生循环依赖等严重问题;第三,对于调用关系异常复杂的业务层、中台层,我们给出了一种点线面结合的方法:
点:流量身份标记注入点
线 1:流量身份标记沿调用链透传
面:紧耦合的服务聚合为服务域
线 2:部署和流量按域切分
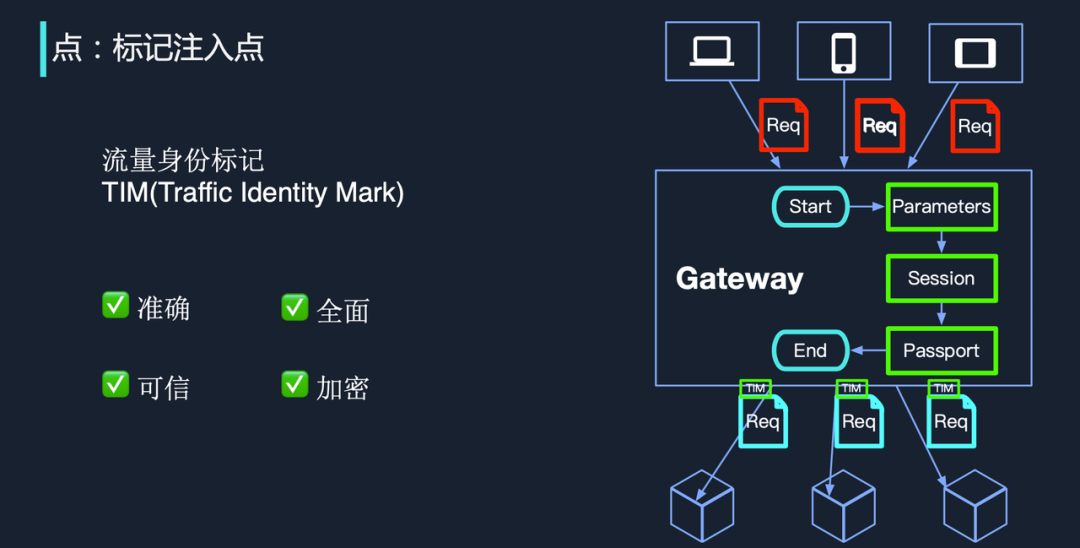
点在字节跳动内部被称为流量身份标记 TIM(Traffic Identity Mark)。流量从客户端进来后,我们会在 Gateway 层对 request 的各种参数进行检测,验证之后,一些需要在链路中传递的核心参数会被记录下来,供后续分流、核心服务调用使用。
这种做法有助于一些特殊链路数据保护策略的实现,如未成年人数据保护。未成年人发出的请求从一开始就带有相关参数,随着调用链向下传递,通过透传机制,核心的中台层和数据服务层依然能读到这些信息,并执行特殊的逻辑,以便对未成年人做好保护。

有了点之后,如果想在下游核心业务中使用这些关键信息,就必须要求信息会向下透传。举个例子,假设抖音的一个请求带有流量身份标记 TIM1,那么该流量触达下游服务时仍应携带标记 TIM1;如果流量来自西瓜视频且携带了 TIM2,那么由这个请求触发下一个在线请求时,它也一定要携带这个 TIM2。这使得整个调用链可以完成串联,类似 Log ID、Trace ID。
所以这个地方有两个依赖,我们最好把 TIM 放在 Header 中,让它能更好地传递信息,并且使下游服务在不解析它的请求 Body 时,就能拿到 Header 中的信息来做流量调度等操作。在一个微服务内部,我们要通过 Context 机制,把入流量和出流量结合起来,把真正的标记传递过去,形成链路。
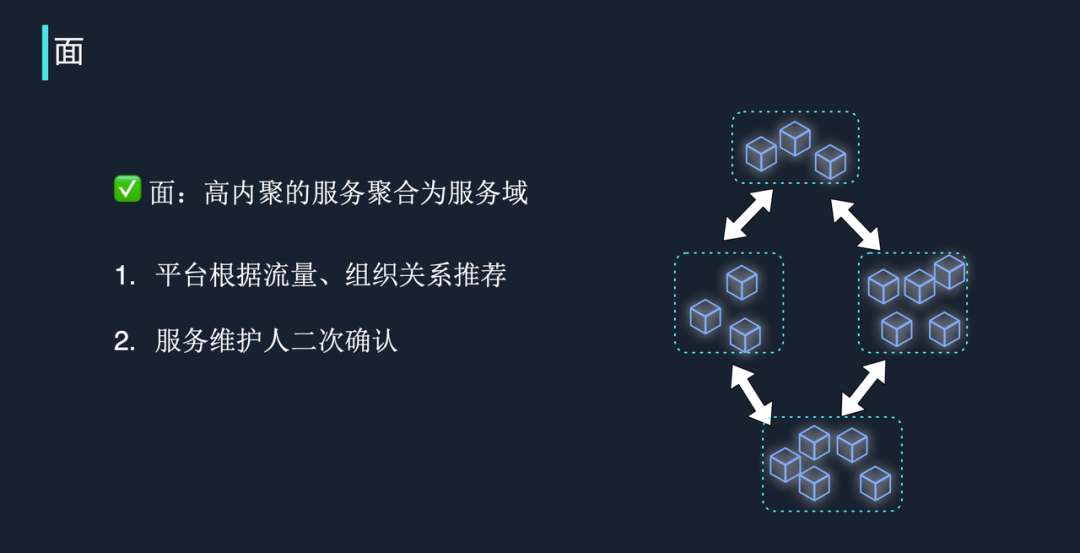
在字节跳动,“面”是指高内聚的服务要聚合成服务域。上文介绍过康威定律,即软件架构受制于组织沟通架构:如果有一组服务,它们的合作和联系非常紧密,相互调度非常多,但是共同对外暴露的功能点又比较少,那么我们就可以把它们聚合为一个服务域。
通过自动搜索流量的紧密、松散程度,结合组织架构关系,我们可以为内部开发者提供服务域自动推荐,但最终设计还是需要服务维护人员进行确认。确定服务域后,服务之间的关系也真正确定下来。紧耦合的服务也需要采用同样的治理策略。
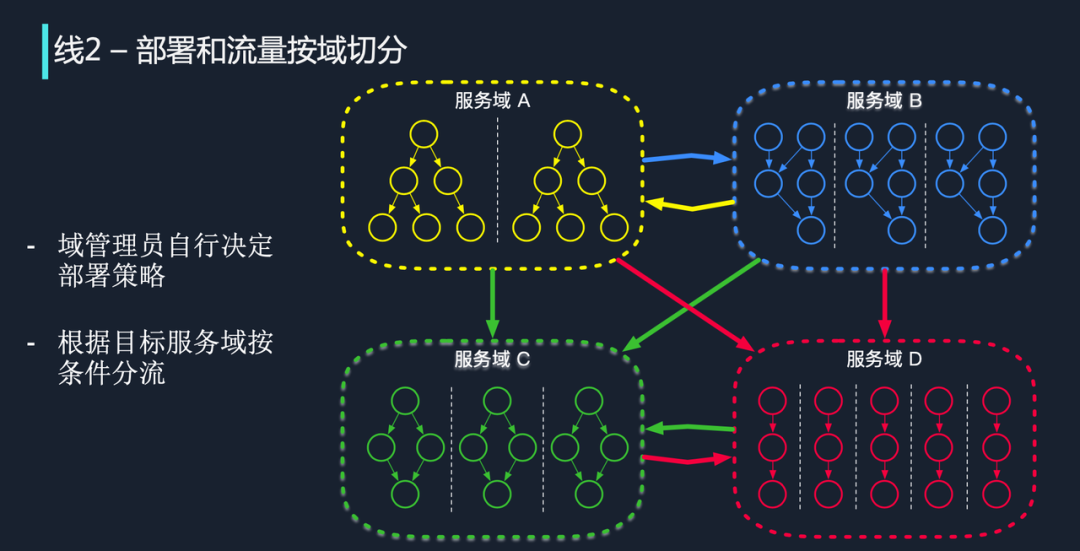
“线 2”有两层含义,一是域管理员自行决定部署策略,二是要根据目标服务域按条件分流。
如上图所示,服务域 A 是一个业务,它的域管理员希望按地域进行切流,把南方的服务调度到左边,把北方的服务调度到右边,他可以自由选择调度的策略。
服务域 C 是一个核心中台服务,比如评论服务,它不应当按照地域进行划分,而是按照 User ID 进行流量划分。基于这个目标,域管理员希望服务域可以按照 ID 取模进行切分,这也是可以的。在服务域内,它就可以形成这样一条泳道,流量可以在泳道中向下传递。
对于服务域之间的流量,在域管理员确定部署策略之后,它会根据目标服务域的调度策略进行分流。举个例子,如果服务域 A 想去访问服务域 C 中的某个服务,流量从 A 出来后,它会根据 C 的切流方式进行切流。字节跳动的绝大多数在线流量已经接入 Service Mesh,我们能够动态分析目标服务的部署策略、切流策略,并反馈给 Client 所在的 mesh proxy,Client mesh proxy 会动态修改目标服务的集群,把流量打到目标集群上去。
当然 Mesh 只是一种方法,开发者也可以用框架或业务代码实现同样的效果,但如果有企业和组织正在内部推广 Service Mesh,上述提到的流量透传、流量注入、根据目标部署情况动态按条件分流等都可以提前放在系统和框架中进行考虑。
在 2021 年抖音央视春晚红包活动中,这套超复杂调用网服务治理思路也有充分应用。活动往往意味着流量激增,容灾测试、全链路压测、容量预估,我们遇到了不少难题。有了这个切流方案后,我们最终较理想地把服务域都找了出来,最终在活动上线后保障了流量的稳定分发,且没有对其他业务造成影响。
04
结语
目前,字节跳动正面临超复杂调用网治理的严峻挑战,它带来的问题是实实在在的。我也相信,随着国内企业的不断发展,很多公司未来也会发展到调用网极其复杂的境地,需要直面同样的问题。为了帮助业务实现健康过渡,大家最好能够做两个布局:
第一个布局是把服务分层做得足够好。可以参考字节跳动的方案,按照分层原则排布服务,使各个组件能够充分发挥优势。
第二个布局是梳理调用链。这一点同样可以参考我们点线面的实践,根据可信的流量标记动态调配流量。
如果这两个布局都能够做好,那么开发者既可以享受微服务的优势,同时也能尽量规避微服务带来的复杂度。
]]>